우리가 일상에서 쉽게 사용하는 콘텐츠 제공 서비스에서는 흔하게 아이템을 추천해주는 기능을 확인할 수 있다.
기존 추천시스템들은 메모리 기반 추천시스템으로, 메모리에 사용자-아이템 정보를 쌓아두는 방식으로 연관성을 파악했다.
다만 이러한 방식은 사용자가 많아지면서 쌓아지고, 듬성듬성한 sparse data로 나타난다는 단점이 있었다.
이러한 단점을 극복하기 위해서 나타난 방식이 모델 기반 추천시스템이고, 자주 등장하는 용어인 Latent Factor에 대해 알아보겠다.
모델 기반 추천시스템이란?
메모리 기반 추천시스템과는 다르게 모델을 생성해 둔 후, 모델을 통해서 추천을 제공하는 방식이다. 요새는 다양한 추천시스템 모델들이 발전하며(LightGCN, MF 등 ... 논문 카테고리에 몇개 정리되어있다.) 생성 시에 많은 연산을 하게되지만, 한 번 모델을 생성해두면 inference 소요시간은 짧다.
이 때 사용자와 아이템 사이에 명백한 연관성을 정의할 수 없는 변수를 잠재변수(latent variable)이라고 한다.
이와 반대로 명백한 기준으로 관측할 수 있는 척도를 관측변수(observed variable)이라고 하는데, latent variable을 도출하기 위해서는 관측변수를 토대로 수학적 모델링을 수행해야 한다.
Matrix Factorization
이름을 그대로 해석하면 '행수 인수분해 모델'인데, 아이템과 사용자 간의 관계를 좌표평면 상의 vector로 나타내는 방식이다. input data 중에서도 explicit한 정보는 사용자가 명백하게 아이템에 관심을 표한 경우이다. 반대로 implicit한 정보는 사용자 behavior로부터 추론한 내용이다.
- explicit feedback data
- 예시) Netflix star ratings, TiVo thumbs up, down
- 보통 sparse한 행렬로 나타난다 - 사용자가 관심을 표시한 아이템만 0 초과의 값이 매핑되기 때문
- implicit feedback data
- 예시) 구매기록, 검색기록, click 기록
특정 서비스로부터 얻은 위와 같은 데이터들을 토대로 Matrix Factorization Model(이하 MF)는 사용자와 아이템들을 모두 공통된 차원 f의 latent factor space에 매핑하여 모델링한다.
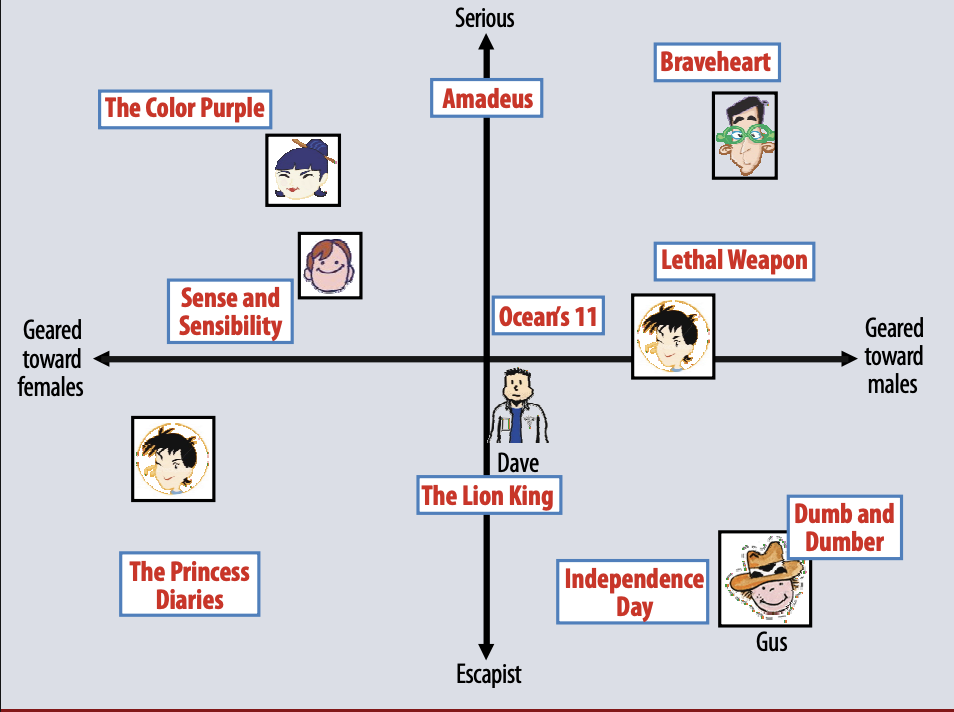
"latent"한 만큼 잠재 요인이 무엇인지 명확하게 파악할 수는 없지만, 사용자와 아이템을 동일한 좌표평면에 매핑함으로서 각 사용자와 아이템 간의 연관성을 거리로 파악할 수 있다.
따라서 어떤 유저 p의 아이템 q에 대한 별점 예측값 r을 구하고 싶다면, latent factor space에서 해당 유저 벡터와 아이템 벡터의 내적을 수행하면 된다.

latent factor vector 구하기
각 사용자와 아이템의 factor vector인 p와 q를 학습시키기 위해서 다음 수식을 이용한다. 이 때 k는 rating 값이 명시되어 있는 (u, i) pair의 집합이다.
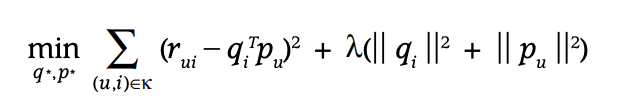
이미 명시되어 있는(explicit) 데이터로 q와 p가 해당 Latent space에서 어떤 좌표값을 나타내는지 학습한다 - 고 이해하면 된다.
=== ref ===
https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
https://velog.io/@soyoun9798/ML-Latent-FactorVariable-%EC%97%90-%EB%8C%80%ED%95%98%EC%97%AC
'AI' 카테고리의 다른 글
| [부스트캠프 AI Tech] RecSys Level 01 KPT 회고 (0) | 2024.09.29 |
|---|---|
| [Python] 자연어처리 - TfidfVectorizer (0) | 2024.07.30 |
| [NLP] 언어모델의 평가 지표 - PPL, BLEU score (2) | 2023.11.21 |
| [PyTorch] Transformers 라이브러리 #2 (2) | 2023.11.01 |
| [PyTorch] Transformer 라이브러리 #1 (0) | 2023.10.30 |