Hugging Face 🤗 사에서 제공하는 Transformers Course를 한국어 버전으로 혼자 공부하며 정리한 글입니다.
- 1장에서 소개한
pipeline()함수를 대체하기 위해, 직접 model과 tokenizer를 함께 사용한다. - tokenizer는 텍스트 입력을 수치 데이터(numerical data)로 변환하고, 이 수치 데이터를 다시 텍스트로 변환하는 기능을 수행한다.
- model은 적합한 모델 아키텍처를 불러와 학습을 진행하는 기능을 수행한다.
- 파이프라인은 전처리, 모델로 입력 전달, 후처리의 3단계를 한 번에 실행한다.
모델 / 토크나이저 불러오기
config()기본 설정에서 모델을 생성하는 방법도 있지만, 보통 사전 학습된 Transformer 모델을 로드해온다.from_pretrained()메서드를 통해서 이 작업을 수행할 수 있다.
from transformers import AutoModel
import torch- checkpoint에 사용하고 싶은 아키텍처를 저장해둔 뒤, 토크나이저와 모델을 해당 아키텍처에서 불러오는 방식으로 사용할 수 있다.
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)
sequence를 인코딩된 id로 변환하기
sequences = ["Hello!", "Cool.", "Nice!"]
encoded_ids = []
for sequence in sequences:
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
encoded_ids.append(ids)
inputs = torch.tensor(encoded_ids)- sequences에 저장된 각 문장을 인코딩 해준다.
- 띄어쓰기가 있는 문장을 포함하고 싶다면 패딩을 추가하는 과정이 필요하다. (추후에 나옴)
output / postprocessing
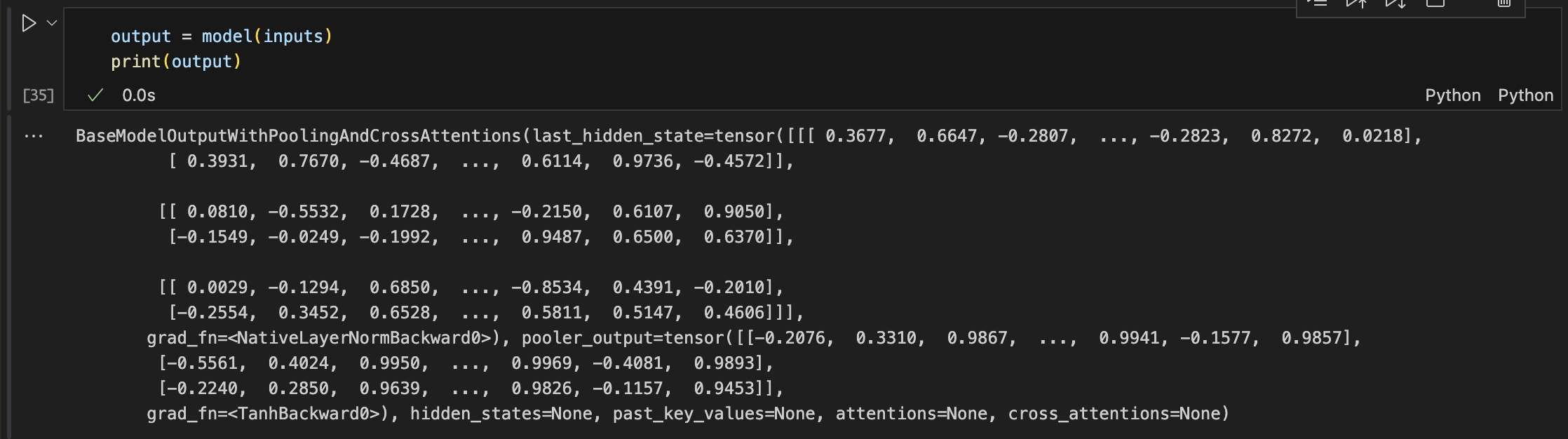
- 현재 모델을 거친 output은 투플 형태로, last_hidden_state, grad_fn 등으로 구성되어 있다. 이 중 softmax를 이용해 last_hidden_state 값을 정규화할 수 있다.

- 참고로 last hidden state는 BERT 모델의 마지막 레이어에서의 은닉 상태로, 최종 결과물에 해당한다.
다중 시퀀스 처리하기
- 모델은 입력의 배치 형태를 요구하고, 단일한 리스트를 입력으로 넣을 시 오류가 발생한다.

- 따라서 input은 무조건 배치 형태(다중 리스트)로 전달해야 한다.
- 아래처럼 리스트로 한 번 더 감싸주면, 차원이 증가하면서 모델을 거칠 수 있게 된다.
input_ids = torch.tensor([ids])padding 추가하기
- tensor는 반드시 직사각형 모양이어야 하기 때문에 모든 input sequence는 크기가 동일해야 한다.
- 문장의 길이들은 전부 다를 수 있기 때문에 max_length를 정한 뒤, 모두 동일한 사이즈가 될 수 있도록 padding을 추가하는 방식을 채택한다.
- 이 때 padding 파라미터를 고려하지 않도록 하기 위해 attention mask를 사용한다.
attention mask 사용하기
batch_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batch_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)- 위처럼 padding 처리한 ID에는 attention mask를 0으로 설정해야 한다.
특수 토큰들
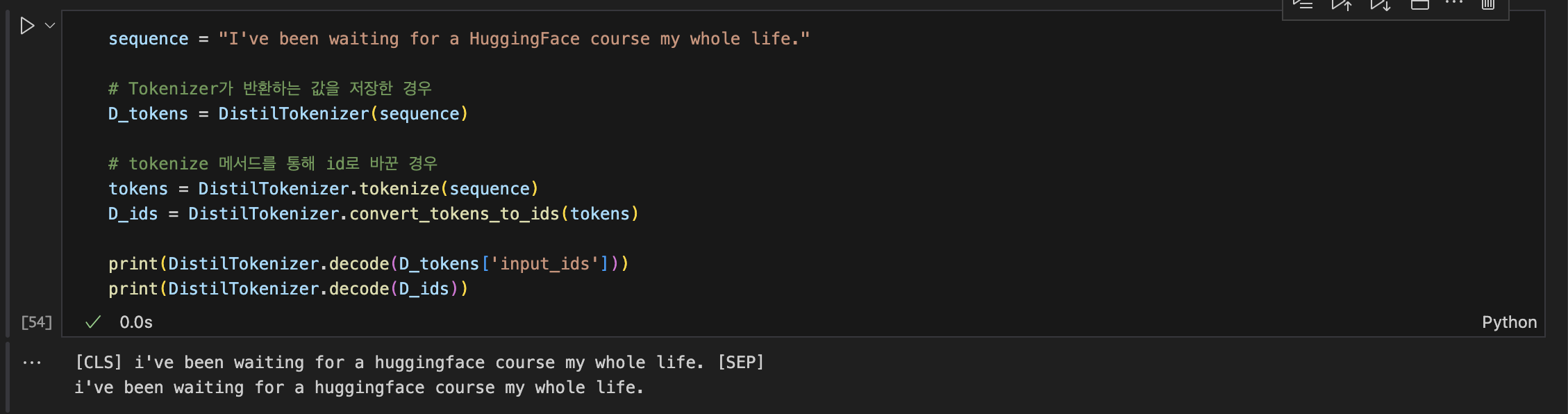
- 토크나이저가 반환하는 값을 바로 디코딩한 경우, CLS/SEP 과 같은 특수 토큰들이 추가된다.
- tokenize 함수를 통해 얻은 token들을 id로 변환한 후 디코딩하면 특수 토큰이 없이 일반 문장으로 디코딩된다.
'AI' 카테고리의 다른 글
| [Python] 자연어처리 - TfidfVectorizer (0) | 2024.07.30 |
|---|---|
| [RecSys] Latent Factor 알아보기 (0) | 2024.03.26 |
| [NLP] 언어모델의 평가 지표 - PPL, BLEU score (2) | 2023.11.21 |
| [PyTorch] Transformer 라이브러리 #1 (0) | 2023.10.30 |
| [PyTorch] M1, M2 칩으로 Pytorch GPU 사용하기 (0) | 2023.08.10 |