Hugging Face 🤗 사에서 제공하는 Transformers Course를 한국어 버전으로 혼자 공부하며 정리한 글입니다.
- Transformers 라이브러리의 첫 번째 도구, pipeline() 함수 이용하기
- 파이프라인 함수에 텍스트가 입력되면, 주요 3가지 단계가 내부적으로 실행된다.
- preprocessing
- 입력 텍스트 모델에 전달
- postprocessing
- zero shot classification 파이프라인에서는 기존에 라이브러리에서 제공하는 레이블이 아닌 새로운 레이블 집합을 사용해서 텍스트를 분류할 수 있도록 하는 classifier이다. pipeline에서 기본적으로 제공하는 라이브러리로 사용할 수 있다.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)- 파이프라인에서는 default model뿐만 아니라 원하는 모델을 선택하여 특정한 작업을 수행할 수도 있다. 아래 코드에서는 pipeline에서 distilgpt2 모델을 선택하여 해당 generator를 사용할 수 있다.
- 이 때 generator는 미완성된 텍스트 생성기로 사용되며, 디코더 모델인 gpt2를 사용한다.
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
# distilgpt2 모델을 로드한다.
generator( "In this course, we will teach you how to", max_length=30, num_return_sequences=2, )** 단일한 문장 감정분석하기
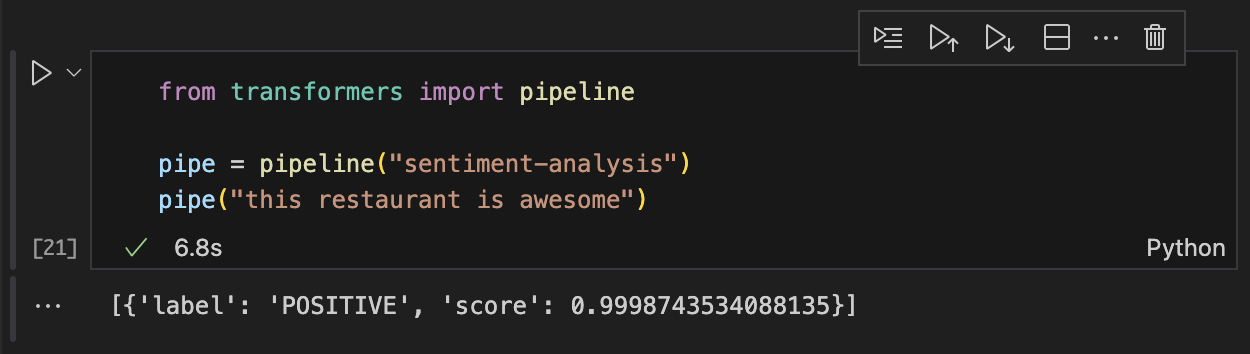
** 다중 문장 감정분석하기

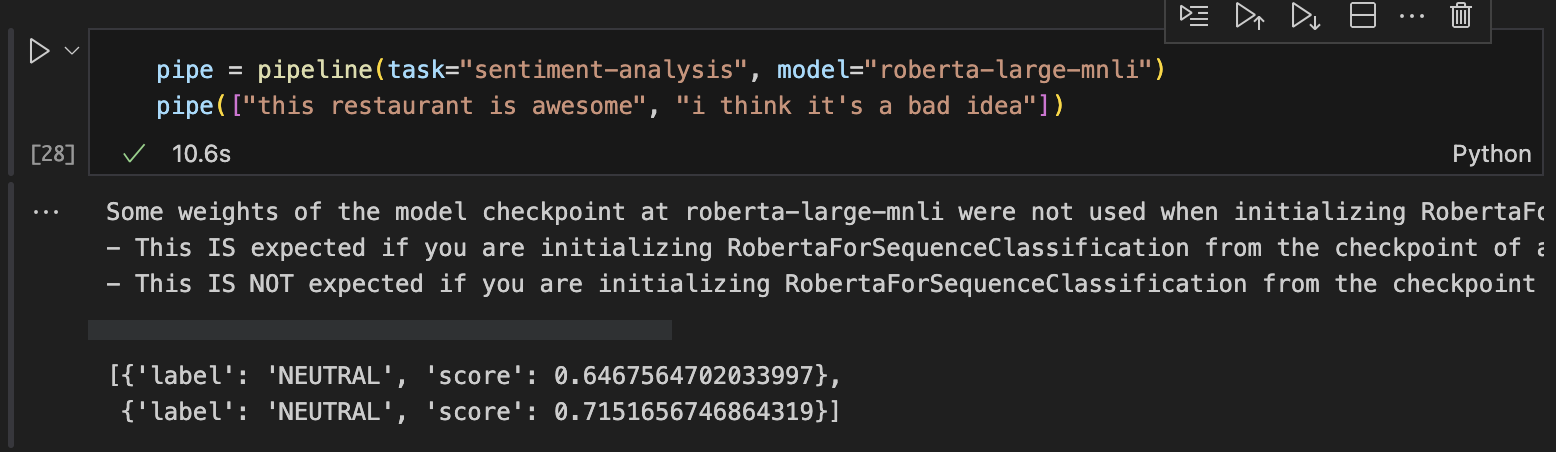
** 특정한 모델(roberta) 가져와서 감정분석하기
Transformer는 어떻게 사용되는가?
- 대부분의 Transformer 모델은 자가지도(self-supervised) 학습 방식으로 학습되었다. 즉, 사람이 직접 데이터에 레이블을 지정할 필요가 없다!
- 전이 학습(Transfer Learning)이란 사전 학습이 수행된 후에 fine-tuning을 진행하게 된다. → 방대한 양의 데이터로 pretrain된 모델에 파인튜닝을 통해서 사용자가 원하는 태스크를 적용할 수 있게 된다는 장점
- Attention layers
- 어텐션 레이어(attention layers)라는 특수 레이어를 통해 단어의 표현을 처리할 때, 문장의 특정 단어들에 특별한 주의(attention)를 기울이고 나머지는 거의 무시하도록 모델에 지시하게 됨
- 어텐션 마스크(attention mask)는 모델이 특정 단어에 주의를 집중하는 것을 방지하도록 함
- 인코더 모델 - 주어진 초기 문장을 손상(mask)시키고, 손상시킨 문장을 원래 문장으로 복원하는 과정을 통해서 모델 학습이 진행됨.
- 디코더 모델 - 일반적으로 문장의 다음 단어 예측 수행으로 이루어지고, 텍스트 생성과 관련된 작업에 적합함 (GPT)대상 작업의 종류에 따라 Transformer의 아키텍처를 변경하여 attention layer를 적용할 수 있다.
'AI' 카테고리의 다른 글
| [Python] 자연어처리 - TfidfVectorizer (0) | 2024.07.30 |
|---|---|
| [RecSys] Latent Factor 알아보기 (0) | 2024.03.26 |
| [NLP] 언어모델의 평가 지표 - PPL, BLEU score (2) | 2023.11.21 |
| [PyTorch] Transformers 라이브러리 #2 (2) | 2023.11.01 |
| [PyTorch] M1, M2 칩으로 Pytorch GPU 사용하기 (0) | 2023.08.10 |