
👩🏻💻 본 포스팅은 개인적 공부를 위해 ResNet을 정리한 포스팅으로, 오류가 있을 수 있습니다.
1. Introduction
- Background, Problem Statement
딥러닝 모델에 있어 network 'depth'의 중요성이 대두되며, deeper networks (layer를 층층이 쌓아 깊게 쌓은 구조)들이 많이 등장하기 시작했다. 다만, layer를 깊게 쌓게 되면 layer를 쌓을수록 정확도가 떨어지는 degradation 문제가 발생한다. 이 degradation 문제는 오버피팅에 의해서 발생하는 것이 아니다(오버피팅이라면 train 에러는 낮되, test 에러는 높아야함). 아래 Figure 1에서 볼 수 있듯 깊은 56번째 layer에서는 train과 test 모두 에러가 발생하는 것을 확인할 수 있다.

즉 레이어가 깊어질수록 optimize 과정이 복잡해지며 training error가 늘어나고, 적절하게 optimize되지 않아서 - 로 추정할 수 있다.
- Solution
본 논문에서는 'deep residual learning framework'를 통해서 레이어가 깊어질 때의 degradation 문제를 해결하고자 한다. 이전의 deep 모델들이 쌓인 레이어에 다음 레이어들이 쭉 이어지는 방식이 아니라 residual mapping은 잔차의 결과를 mapping하도록 하는 것이다.
기존에는 H(x)를 매핑하여 쭉 진행하는 방식이었다면, 우측의 Residual Block은 H(x) = F(x) + x 를 학습시키게 된다. 즉, 기존의 입력값인 x와 잔차 F(x) (=H(x)-x)를 동시에 학습시킬 수 있게 되는 것이다. 본 논문은 residual mapping이 기존의 mapping보다 최적화하기 가볍고 쉽다고 주장한다.
이렇게 formulation F(x)+x를 학습하며 "shortcut connections"를 구성하게 된다. 자기 자신인 identity(=x) 로 매핑을 수행하고, 그 결과를 마지막 레이어에 더하는 구조로, input x에서 output쪽으로 바로 넘어가는 shortcut 연결로 구성되어있다.
-Importance
저자들은 논문의 목표를 총 두 가지로 설정한다.
- plain net(단순히 레이어를 쌓는 구조)와 비교하였을 때 더 높은 최적화 성능을 보여야 함.
- depth가 증가함에도 쉽게 accuracy를 높여야 함.
ResNet 아키텍처는 결과적으로 ImageNet, CIFAR-10 모두에서 우수한 성능을 보였다. 특히나 ImageNet에 적용된 모델 중에서 가장 깊은 레이어를 가지고 있었는데, 그럼에도 불구하고 VGGnet(대표적인 CNN기반 모델)보다도 덜 복잡한 구조를 유지할 수 있었다고 한다.
2. Related Works
Residual Representations.
영상처리 모델인 VLAD, Fisher Vector 등에 의하면 벡터 연산을 수행할 때 또한 image retrieval, classification 항목에서 잔차 벡터를 사용하는 것이 일반 벡터를 사용할 때보다 더 효과적이었다고 한다. 합리적인 재구성과 전처리 과정은 최적화 과정을 더 간단하고 가볍게 해준다고 언급한다.
Shortcut Connections.
이전의 많은 neural net 연구에서도 살펴볼 수 있듯이, shortcut connection은 오랜 기간 언급되어 왔다. Residual block에서 사용되는 shortcut connection은 파라미터에 구애받지 않고, x가 0에 수렴하지 않기 때문에 항상 residual function을 학습하게 된다고 한다.
3. Proposed Idea
Residual Learning
H(x)는 기본 매핑이 되고, x를 input으로 가질 때에 다수의 비선형 레이어를 거치는, 복잡한 함수 과정이더라도 근사가 가능하다면 잔차 함수 H(x) - x 또한 근사가 가능해지게 된다. 다만 잔차 함수가 일반 함수에 비해 학습의 복잡도(ease of learning)가 낮으므로, Residual function을 이용한 연산을 수행하는 것이 더 용이하다.
Identity Mapping by Shortcuts
ResNet은 building block에서 위 식과 같은 연산을 수행하여 하나 이상의 레이어를 skip한다.
식 1은 input x는 (F + x) 함수를 통해 shortcut, 일반 행렬곱 연산을 거친다. 이와 같은 연산을 하려면 input x와 F의 dimension은 동일해야 한다. 동일하지 않은 경우 식 2를 이용해서 dimension을 맞춰줄 수 있는데, 여기서 행렬 Ws를 통해 x에 linear projection(행렬곱)을 수행하여 차원을 동기화시킨다.
Network Architectures
Plain Network
ResNet은 baseline으로 VGGnet의 구조를 사용하였으며, 3 x 3 conv filter를 적용하였다.
- 동일한 피처맵 사이즈를 가질 경우, 그 레이어들은 모두 동일한 필터의 개수를 가짐
- 레이어 당 시간복잡도를 통일시키기 위해 피처맵의 사이즈가 1/2이 될 경우, 필터의 개수는 2배로 적용됨
각 conv 필터는 stride=2로 설정하여 downsampling을 진행하고, average pooling layer를 거쳐 softmax 함수로 1000-way FC 레이어를 통과한다.
-> 이미 baseline만으로도 필터 수도 줄어들고 복잡도가 감소하기에, 기존 VGG19에 비해 18%(82% 줄어든)의 연산만 수행하게 된다.
Residual Network
위의 Plain Network에 shortcut connection만 추가한 네트워크이다. 위에서 언급했듯이 identity shortcut은 input과 output을 같은 차원으로 맞춰줘야 하는데, output의 차원이 input에 비해 증가할 경우
- zero padding을 추가함
- projection shortcut (식 2) 수행
을 진행하여 input x와 output F(x) 간의 dimension을 맞추어 shortcut 연산을 진행하게 됩니다.
Implementation
-
image resized 224 * 224
-
Batch normalization BN 사용
-
Initialize Weights
-
SGD, mini batch 256
-
Learning rate 0.1 (학습이 정체될 때 10씩 나눠준다고 함. ex) 0.1 -> 0.01 -> 0.001 ... )
-
weight decay 0.0001, momentum 0.9
-
No dropout
4. Experiments
저자들은 ResNet 아키텍처 내에서 여러가지 데이터셋, plain · residual 구조들을 적용하며 실험을 진행하였다.
4.1. ImageNet Classification
2012년에 진행된 ImageNet dataset으로 실험을 진행하였고, 1000개의 class로 classify하는 과정을 거쳤다.
- Plain Networks
plain net으로 쌓을 경우에는 18-layer와 34-layer의 경우에는 모두 degradation으로 인해 높은 에러율을 보였다. 결론적으로는 저자들도 optimization difficulty들을 나중에 연구해보겠다고 말하고 마무리 됨 ..
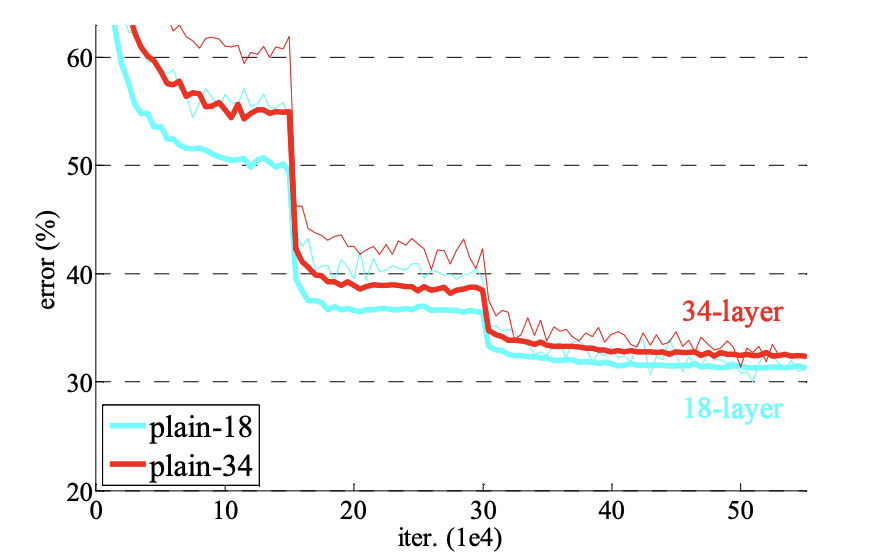
- Residual Networks
plain network와 동일한 베이스라인을 사용하지만, 중간에 shortcut connection을 삽입한 residual network이다. 실험 결과 다음과 같이 3가지 관찰 결과를 확인할 수 있다.


1. plain network과 반대로 34-layer의 결과가 18-layer보다 좋다. 특히나 Residual Network 34-layer로 진행한 실험 결과는 validation 성능 또한 높아져 degradation 문제의 해결이 이루어졌음을 확인할 수 있다.
2. residual network에서는 18-layer에 비해 34-layer의 정확도가 올라가기에, depth가 증가할 때 정확도도 함께 올라감을 확인할 수 있다. 결론적으로 extremely deep system에서도 효과적인 성능을 보이는 것이다.
3. 18-layer를 바탕으로 비교했을 때 plain과 residual net의 acurracy는 큰 차이 없음을 Table 2에서 확인할 수 있다. 다만, ResNet의 수렴이 더 빨랐기에 "not overly deep" 상황에서는 ResNet이 optimization하기 더 쉬운 구조임을 관찰할 수 있다.
- Identity vs Projection Shortcuts
training 과정에서는 parameter-free, identity shortcuts을 사용할 경우 학습에 도움이 되었다. Projection shortcut을 적용할 때에는 어떤 변화가 있는지 알아보았다.
Projection Shortcut을 적용하는 3가지 방법
A. 차원 증가를 위해 zero-padding을 사용하는 경우 (parameter-free)
B. 차원 증가를 위해 projection shortcuts을 사용 (위의 식 2의 Ws)
C. 모든 shortcut들을 projection으로 적용한 경우
실험 결과 C가 미미한 성능차로 가장 우수했지만, 아래에서 소개될 bottleneck architecture에서 Identity shortcuts가 복잡도를 낮게 유지하는 데에 중요한 역할을 하기 때문에 C option은 더 이상 사용하지 않았다고 한다.
- Deeper Bottleneck Architectures
학습시간의 단축을 위해 ResNet의 building block을 병목 구조(bottleneck architecture)로 설계하였는데, 각 residual function F는 3개의 레이어로 이루어져있다. 1x1 레이어는 차원을 줄이고 늘리는 역할을 하는데, 결론적으로 3x3 레이어의 input과 output은 작은 dimension으로 유지할 수 있도록 한다.
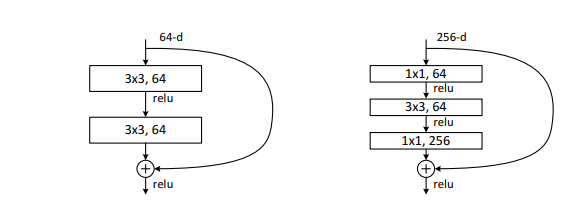
이 때 identity shortcut 대신 projection shortcut이 사용되었다면 모델 사이즈, 시간복잡도가 2배 늘었을 것이다. 결론적으로 identity shortcut은 bottleneck 디자인에 적합하다.
references