추천시스템 프로젝트 시작하면서 급하게 읽는 GCN .. 💃🏻 수식이 너무 어려워용
👩🏻💻 본 포스팅은 개인적 공부를 위해 논문 LightGCN을 정리한 포스팅으로, 오류가 있을 수 있습니다.
1. Introduction
LightGCN은 GCN에서 협업 필터링에 필요한 부분만 살린 모델로, 특히 GCN을 계승한 NGCF의 약점을 보완한다는 특징이 있다. Contribution은 다음과 같다.
- GCN 모델에 사용된 feautre transformation과 nonlinear activation 단계를 제거해, 협업 필터링에 의미 없고 연산량만 잡아먹는 연산을 제거한다.
- GCN의 아키텍처 중에서도 추천에 가장 의미있는 컴퍼넌트들만 선정한 추천시스템을 구축한다.
2. Preliminaries
GCN - 애초에 그래프 내에서 노드 분류(node classification)을 위한 모델이므로, 각 노드는 상당히 많은 피처를 지니고 있음.
CF에서 활용되는 user-item 상호작용은 원핫 벡터로 표현되며, identifier 이외의 역할은 하지 않는다. 즉 어떤 노드인지 식별만 가능하지, 각 노드의 특성을 파악하기는 어렵다.
따라서, NGCF는 다수의 비선형 층으로 학습하는 것이 강점인 Neural Network에는 적합하지 않은 인풋이라고 볼 수 있다.
NGCF의 약점
- GCN에서 수행되는 연산 두가지 - feature transformation, nonlinear activation 연산을 전부 사용하는데, 오히려 Collaborative FIltering을 위한 GNN 성능을 떨어뜨리는 요인이 되었다고 한다.
- LightGCN은 쓸데 없는 연산은 버리고, GCN의 가장 핵심적인 연산 neighborhood aggregation만을 활용한 Collaborative Filtering 모델이다.
- GCN은 본래 semi-supervise node classification 모델이며, 각 노드가 semantic feature를 많이 지니고 있어야 의미가 있다.
왜냐? -> 여러층의 비선형 계산을 위해서는 feature learning에 효과적이기 때문이다.
- 그러나, NGCF가 채택한 Collaborative Filtering은 user-item interaction이 다양한 feature를 가지지 않는 단일한 ID를 가지기 때문에 feature learning은 무의미하다.
=> 결론적으로 추천시스템을 구축할 때는 smoothing을 위한 각 연산이 정말 필요한 연산인지 철저히 확인하는 단계가 필요한다고 주장한다.
NGCF 저자들 울겄다 ...
3. METHOD
input : e<i>, e<u> - 사용자와 아이템의 임베딩 값
output : 예측값 prediction y
기존 GCN은 그래프의 피처를 smooth하게 만들어 각 노드의 representation을 학습한다. 이 때 GCN은 graph convolution을 채택하는데, 이웃들의 피처를 종합하여 그래프의 각 노드들을 재생성한다. 이렇게 종합하여 재생성하는 과정을 neighborhood aggregation이라고 한다.
LightGCN은 기본적으로 feature smoothing을 통해 각 노드 간의 연관성을 파악하도록 한다.
feature smoothing이란?
이웃 노드 간의 거리를 줄여 classification을 쉬워지게끔 함
3.1.1 LGC (Light Graph Convolution)
각 아이템, 유저 벡터 간에 단순한 weighted sum만을 수행하고 별도의 가중치는 학습시키지 않는다. 즉, training 과정에서 학습 및 업데이트 되는 파라미터는 0번째 레이어의 item, user들의 임베딩 벡터 뿐이다. 이 부분이 NGCF와의 차이점이다.

- 따라서 LightGCN은 NGCF에서 사용되었던 불필요한 가중치 학습, 계산 시간을 줄이고 컴팩트하게 필요한 user-item간의 정보 선에서만 모델을 학습시키게 된다.
- 또한 self-connection이 별도로 존재하지 않는다. 예를 들어 사용자 u1에 대한 예측이라면, u1 피처는 없이 이웃 노드들과의 연관성만 고려한다.
- -> self-connection은 layer propagation, combination 단계에서 처리하므로 각 convolution 단계에서는 상관없음 (뒤에서 자세히)
3.1.2 Layer Combination and Model Prediction
k개의 레이어를 전부 지나고 나면 여태까지 각 레이어에서 구했던 임베딩 값들을 (weighted sum)더해준다. 학습되며 변경되는 파라미터는 0번째 레이어의 임베딩밖에 없다고 했는데 어떻게 가중치를 구하는지 의문점이 들었다.
=> 논문에서는 하이퍼파라미터로 취급해도 되고 따로 어텐션 메커니즘을 이용해 alpha를 정의해줘도 된다고 써있음
그러나 이들은 "Light"한 GCN임을 강조하기 위해 레이어 전반을 다루는 matrix weight은 존재하지 않고, 매 레이어마다 1/(K+1)를 곱하도록 설정했다고 한다.

이들이 layer combination을 통해 최종 값을 구한 이유는 다음과 같다.
1. layer를 거칠수록 node는 over-smoothing되기 때문에, 마지막 단일 레이어만을 사용하기엔 위험성이 있다.
over-smoothing
오버피팅의 개념처럼 과도하게 노드들이 수렴하는 현상
2. 각 layer마다 서로 다른 semantic을 추출할 수 있다. 여러개의 layer를 전부 고려하면, 결과가 더 많은 feature들을 고려한 셈이 된다.
3. Self-connection이 가능해진다.
사용자와 아이템간의 최종 예측값은 다음과 같으며, 추천시스템이 돌아갈 때 ranking score로 작용하게 된다.


사용자 u와 아이템 v의 임베딩을 계산해서 각 관계성마다 Score를 도출하여 ranking score를 매길 수 있다.
3.1.3 Matrix Form
사용자와 아이템 간의 상호작용 행렬 : R
행렬 R의 각 Entry : 연관성이 있다면 1, 없다면 0


E는 각 레이어의 임베딩값을 전부 더한 값이 된다.
=> 즉, 여러 층의 레이어들을 거치면서 한 사용자와 연관된 item과 user 임베딩을 전부 고려한 상태이다.
3.2 Model Analysis
3.2.1 Self Connection
- identity matrix I 구축
- identity matrix - self connection을 고려하여 위에서 구한 adjacency matrix에 더하는 작업
- 이로써 LGC 레이어에 self-connection을 반영해, 이전 convolutional graph 모델들과 결과적으로는 똑같이 self-connection 정보를 얻을 수 있음
3.2.2 APPNP
- 개인화된 추천시스템을 위해, APPNP은 over-smoothing을 방지할 수 있도록 각 propagation 레이어에 locality와 neighborhood 정보를 전부 유지할 수 있도록 하는 feature를 추가했음
- layer가 높아질수록 노드들이 비슷한 값을 지니게 되는데, 파라미터 Beta를 추가함

3.2.3 second-Order Embedding Smoothness
위에서 over-smoothing을 방지하는 방법을 알아봤다면, 임베딩을 smoothing하는 방법도 알아봐야 한다.
검증을 위해 k=2인 LightGCN을 설정한다.


- coefficient를 설정해 유저 u와 v 사이의 관계성을 나타낸다.
- 유저 u에 대한 유저 v의 영향력을 고려하기 위해서는 세 가지 기준을 따른다.
- 두 유저와 모두 상호작용한 아이템의 개수(=> 많을 수록 coef 증가함)
- 위 아이템들의 유명한 정도 (=> 높을수록 개인화된 영역이 아니므로, 유명할 수록 coef는 줄어듦)
- 유저 v의 활동 정도(=> 덜 활동적일수록 coef 증가함)
위 조건들을 고려하여 coefficient를 설정하면 유사한 사용자들을 잘 골라 CF를 진행할 수 있다.
3.3 Model Training
- LightGCN의 구조 중에서 유일하게 업데이트 되는 파라미터는 0번째 레이어의 임베딩이다. 기본 MF 구조와 똑같은 복잡도를 지니므로 베이지안 loss를 채택해 사용한다.
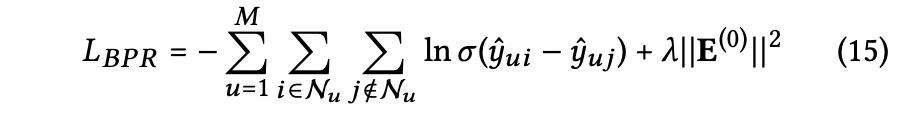
4.4.3 Ablation - Analysis of Embedding Smoothness
Ablation study 중에서도 임베딩의 smoothness를 검증하는 실험을 정리해보려 한다.
(내가 제일 이해가 안됐던 부분이라 ...)
over-smoothing되어도 안되고, smoothness를 정의하는 수식은 다음과 같다.
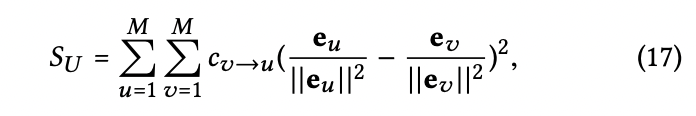
2-layer LightGCN은 상호작용이 있었던 아이템과 관련 있는 사용자들과의 smoothing strength(위에서 본 coef)를 계산한다.
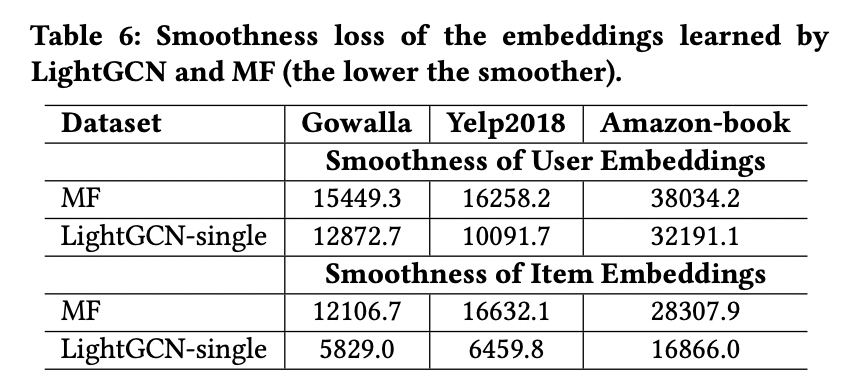
임베딩이 smoothing된 정도가 LightGCN의 척도를 나타내는데, 아래 table 6를 참고하면 기본 MF보다 smoothing된 정도가 향상된 것을 확인할 수 있다.
=== references ===