
👩🏻💻 본 포스팅은 개인적 공부를 위해 논문 KGAT를 정리한 포스팅으로, 오류가 있을 수 있습니다.
이전에 포스팅했던 LightGCN은 GCN의 연장선으로, 사용자와 아이템 간의 연관성을 고려하는 가벼운 모델이었다. 그러나 우리 프로젝트가 가지고 있는 데이터와 목표로 하는 모델링은 유저와 유저 간의 연관성도 고려해야 했기에, 따라서 협업 필터링 + knowledge graph까지 합쳐진 하이브리드 모델을 알아봐야 하는 상황이었다.
Background
- CF(Collaborative Filtering) : 동일한 아이템에 관심 있는 비슷한 사용자에 집중한다.
- SL(Supervised Learning) : 아이템 - 속성의 연관성에 집중한다.
- KG(Knowledge Graph) : entity-relation-entity의 triplet(나는 아이템, 속성의 관계쌍으로 이해했다)을 지닌다.
- core set : 데이터 중에서도 core, 즉 중요하고 유의미한 정보를 담고 있는 top-k 데이터셋을 의미한다.
- triplet : 삼중항 네트워크 (이 포스팅에서는 관계쌍으로 칭함)
Task Formulation
- KGAT는 이전 모델들에 비해 무엇보다 end-to-end로 유저, 아이템, 속성과의 관계를 모두 고려한 모델임을 강조한다.

- KGAT의 인풋이 되는 collaborative knowledge graph G는 위와 같이 구성한다.
- 아이템 속성과 외부지식 뿐만 아니라 사용자 간의 관계성까지 파악할 수 있는 지식 그래프를 구성해야 한다. (즉, 이미 인풋 데이터 딴에서 knowledge graph 형태로 처리가 되어있어야 함)
- CKG의 figure와 수식을 나타내면 위와 같은데, 이전 모델과 다르게 user와 entity 간의 속성까지 고려할 수 있다는 특징이 있다.
유저 - 아이템 - 엔티티 간의 고차원 연결관계를 설명하기 위해 사용되는데, 각 관계성을 독립적으로 도출한다.
(entity : 아이템 혹은 속성)
Methodology
3.1. Embedding Layer
임베딩 레이어의 궁극적인 목적은 구축한 input 지식 그래프의 entity와 관계들을 벡터로 나타내는 것이다. 지식 그래프 상에 (h,r,t) 관계쌍이 존재한다면, 해당 triplet(관계쌍)의 plausibility score는 다음과 같다.
score g는 낮을수록 h - r - t 관계성이 뚜렷함을 의미한다. 가중치 W_r는 관계 r의 transformation matrix에 해당하고, 각 가중치와 기존 entity head와 tail을 곱하는 수식은 entity를 relation 공간으로 사영하는 것과 동일한 의미이다. 즉, 각 entity(아이템 혹은 사용자, 속성)들의 '특정 관계'에서의 유사도를 파악하기 위해 plausibility score를 사용하는 것이다.
이렇게 entity h와 t를 relation 공간에서 나타내는 과정을 TransR이라고 한다. TransR을 통헤서 entity간의 연관성이 존재하는지 확인할 수 있고, 해당 연관성이 높은 아이템들을 찾기 위해 사용된다.
<pairwise ranking loss>
TransR의 loss 함수에 대해 이해하기 이전, Pairwise Ranking Loss에 대해 이해해야 한다. 사용자가 볼법한 영화의 순위를 매겨 제공하는 task가 있다고 하자. 영화 item
KGAT에서는 이를 어떻게 적용할 수 있을지 살펴보자면, 사용자와 연관이 있는 entity인
사후 확률을 최대화할 수 있는 파라미터를 찾기 위해 loss 값을 최소화해야 한다. 이를 위해서는 선호할만한 아이템
최종 r 파라미터의 공간 상에 entity h와 t를 사영한 값이 최종 embedding값이 된다.
3.2 Attentive Embedding Propagation Layers
노드 간의 연결에 가중치를 부여하기 위해 graph attention network를 적용한다. 중요한 관계에는 더 큰 값을 부여하기 위해 총 세 개의 레이어를 거치게 된다.
1) Information Propagation
-
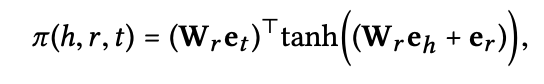
공간 r 상에서
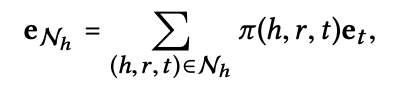
2) Information Aggregation

entity head의 네트워크 임베딩인
3) High-order Propagation

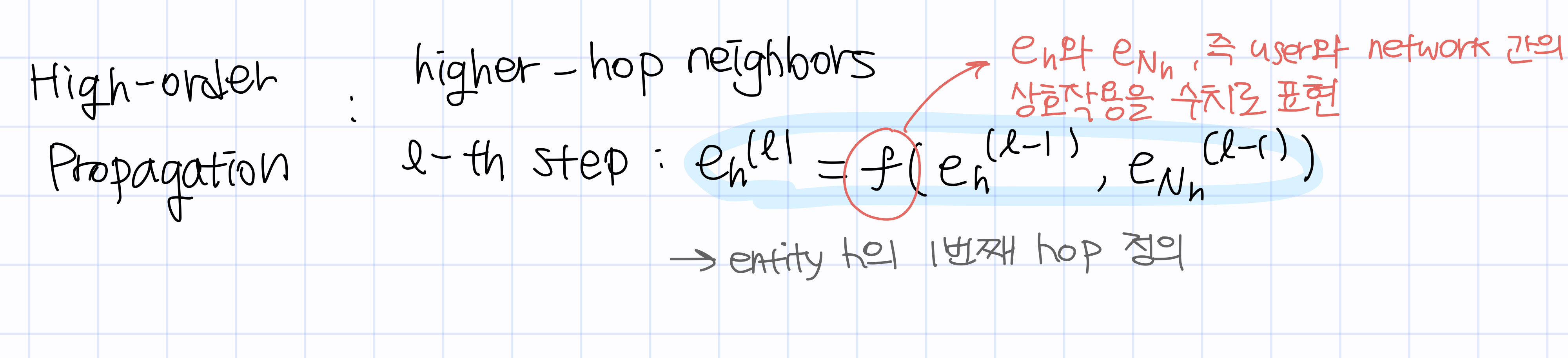
이와 같이 각
3.3 Model Prediction

High-order propagation 단계를 통해 단일 유저 노드의 representation 리스트를 얻게 된다.
concatenation 과정으로 각 entity를 나타내는 단일 벡터로 나타낸다. 이렇게 user와 item의 임베딩 값을 얻은 후, Prediction 값인 y를 얻을 수 있다.

3.4 Optimization
위에서 봤던 KG loss와 CF loss를 별도로 정의한 후 합쳐 KGAT의 최종 loss function을 구성한다.

CF loss는 Bayesian Personalized Ranking 함수를 채택해 아이템 i와 j 사이의 거리가 멀어지도록 한다. 이 BPR loss는 긍정적 신호와 부정적 신호를 받은 각 아이템들을 더욱 편향되도록 하는 함수인데, 다음에 자세한
포스팅으로 남기도록 하겠다.

Conclusion
이 논문이 기여한 바는, 기존 CKG(collaborative knowledge graph)에서 나아가 더 고차원의 연결관계까지 고려할 수 있는 KGAT를 제시한다는 것이다. 특히나 attention 모듈을 도입해 기존 노드의 임베딩이 관계성을 잘 나타내는 방향으로 업데이트하며 end-to-end fashion으로 모델링을 진행하였다.
=== ref ===