👩🏻💻 본 포스팅은 개인적 공부를 위해 논문 RecVAE를 정리한 포스팅으로, 오류가 있을 수 있습니다.
Abstract
RecVAE는 Mult-VAE에서 발전한 추천시스템 모델로, variational autoencoder를 채택했다.
원래 VAE 구조는 생성형 모델에서 많이 사용되지만, 데이터의 표현력을 높이는 parameter를 찾는 representation learning에도 사용된다는 것이 특징이다.
기존 Mult-VAE와 비교했을 때 개선된 점은 다음과 같다.
- prior distribution 추가 ⇒ 이전 인코더의 파라미터 사용 가능
- KL term 반영을 위한 $\beta$ hyperparam 추가
- alternating update 학습
- 인코더 구조 변경
Background
+) Autoencoders and Regularization for Collaborative Filtering
user-item matrix $X$가 있고, $X$의 한 행에 해당하는 사용자 $X_u$로 나타낸다.
$x_u$와 $x_u$의 일부의 1을 0으로 세팅한 $\tilde{x_u}$가 있을 때, $\tilde{x_u}$로부터 $x_u$를 재건하도록 학습
가장 간단한 구조인 CDAE
- $W$: input-to-hidden weight, $W'$: hidden-to-output weight
- $\tilde{x_u} = \sigma(W' z_u + b')$
$z_u = \sigma(W^\top\tilde{x_u}+V_u)+b)$
+) Mult-VAE
multinomial likelihood vae
최종 목적: 유저의 피드백 데이터를 유저 임베딩 $x_u$으로 변환
1) latent representation log-likelihood
$\sum\limits_{i}x_{ui}log \pi_i (z_u)$
2) CF의 confidence weight 반영한 logistic log-likelihood
$\sum\limits_{i}x_{ui}log \sigma(f_{ui})+(1-x_{ui})log(1-\sigma(f_{ui}))$
Multinomial Distribution:
BoW에서도 사용되는 개념으로, $N$개 중 $k$개 item 뽑을 확률을 나타냄
$N$: 유저가 클릭한 아이템 개수
- one-of-K case PMF: $p(x|\pi, n) = \dbinom {n!}{x_1!x_2!...x_k!}\Pi_{i=1}^k \pi_i^{x^i}$
- $z_u \sim N(0, 1)$, $\pi(z_u) = \text{softmax}(f_\theta(z_u))$
- $z_u$: k차원의 유저 representation
- $f_\theta: \mathbb{R}^k → \mathbb{R}^{|I|}$, neural network으로 user representation 표현력 강화
- $\theta$를 추정하기 위해 variational approximation $q(z_u)$ 설정
- $x_u \sim \text{Mult}(n_u, \pi(z_u))$
- $n_u$: 사용자가 만든 인터랙션의 수
Variational Inference:
- $q_\phi(z_u|x_u)$가 $p(z_u)$와 유사해지도록 KL Divergence 도입해 학습
Proposed Approach
1. Mult-VAE encoder의 발전
Encoder
- mean, covariance matrix 예측하는 inference network 수정 ⇒ dense CNN과 swish activation function, layer norm 구조로 변경
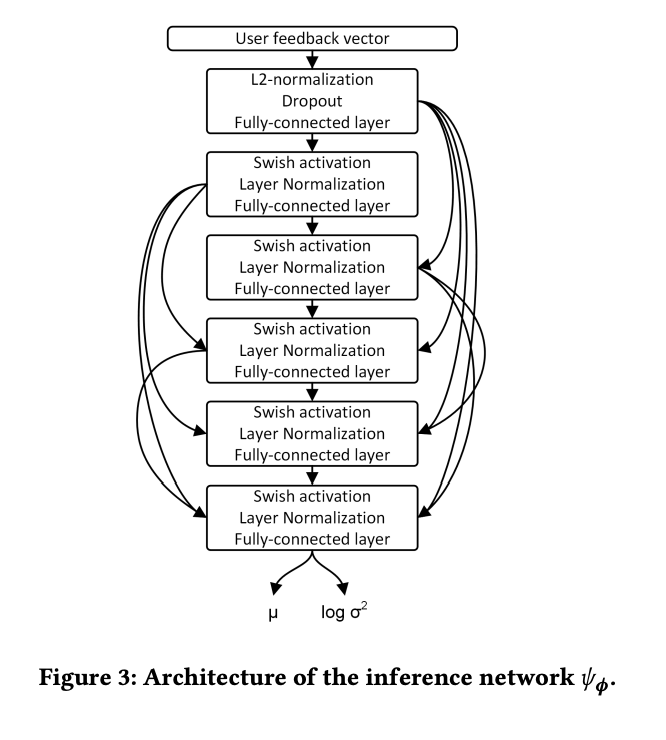
Decoder
- $f_\theta(z_u) = Wz_u + b$로, $W$와 $b$는 item embedding, bias로 이해할 수 있다.
2. Composite Prior
- 기존 Mult-VAE는 posterior 분포를 갱신할 때 variational parameter $\phi$가 손상되어 다른 데이터들이 Forget되는 단점이 있다.
⇒ 해결: 이전 epoch의 파라미터 $\phi_{old}$를 사용 - $p(z|\phi_{old},x) = \alpha N(z|0,I)+(1-\alpha)q_{\phi_{old}}(z|x)$
추정된 posterior, likelihood는 variational parameter $\phi$로부터 조건부 독립이 된다. -
요런식으로 이전 인코더의 값들을 저장해두게 된다.self.prior = CompositePrior(hidden_dim, latent_dim, input_dim) def update_prior(self): self.prior.encoder_old.load_state_dict(deepcopy(self.encoder.state_dict()))
3. Rescaling KL Divergence
- $\beta$ - VAE framework: $\beta$를 0부터 1까지 KL-annealing하는 것과 같은 시도가 나오긴 했지만, RecVAE 구조에서는$\beta$의 annealing이 유의미한 결과를 보이지 못함 ⇒ scaling factor 고정하기로 결정
- $\beta' = \gamma \sum\limits_{i} x_{ui}$
$\beta$를 annealing하는 방식으로 찾는것을 대신해 user rating을 sum한 값과 $\gamma$를 곱한 값을 scaling factor로 설정한다.
4. Alternating Training and Regularization by Denoising
ALS의 방법 차용 ⇒ user와 item embedding을 번갈아 가며 업데이트
- User Embedding: 모두 일괄적으로 학습된 뒤, 추론 네트워크에서 분할된다
Item Embedding: 학습 과정에서 개별적으로 계속 학습된다

- 인코더에서 $\phi$ 학습, 디코더에서 $\theta$ 학습
- 인코더가 더 복잡한 구조이기 때문에 $\theta$가 한 번 업데이트될 때마다 인코더의 파라미터는 $\phi$는 여러번 업데이트 된다.
run(opts=[optimizer_encoder], n_epochs=args.n_enc_epochs, dropout_rate=0.5, **learning_kwargs)
model.update_prior()
run(opts=[optimizer_decoder], n_epochs=args.n_dec_epochs, dropout_rate=0, **learning_kwargs)Summary
- VAE 구조로 input data가 재건될 때, observed feedback 뿐 아니라 unobserved feedback까지 반영한 generalized representation을 위해 denoising 단계가 필요하다.
- 인코더에는 denoising 단계를 반영해 $\theta$를 업데이트하고, 디코더에는 denoising 단계가 없는 vanilla VAE 구조를 사용한다. (오히려 정규화 때문에 성능이 하락하기도 해서 overregularize를 방지해야 한다.)
- 최종 ELBO loss function
기존 Mult-VAE의 loss 함수를 그대로 사용하되, KL Divergence 항에서 이전 인코더의 파라미터를 사용한다는 점이 다르다.
input data가 크게 손상되지 않게 하기 위해 디코더의 loss 함수는 $\theta$의 update를 담당한다.

- 초기 학습 과정에서 인터랙션 데이터가 없었던 사용자에 대해서도 test time feedback $x$로 inference network로 유저 임베딩을 생성해, 학습된 decoder $p_\theta(x|z)$로 top item을 추출할 수 있다.